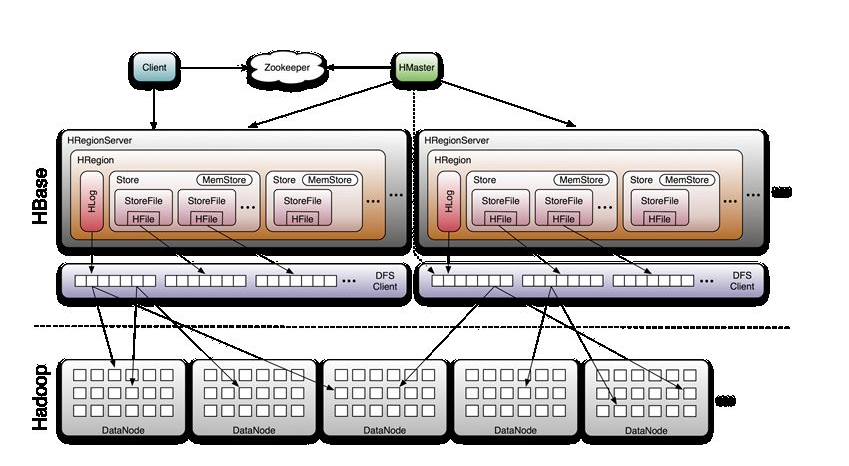
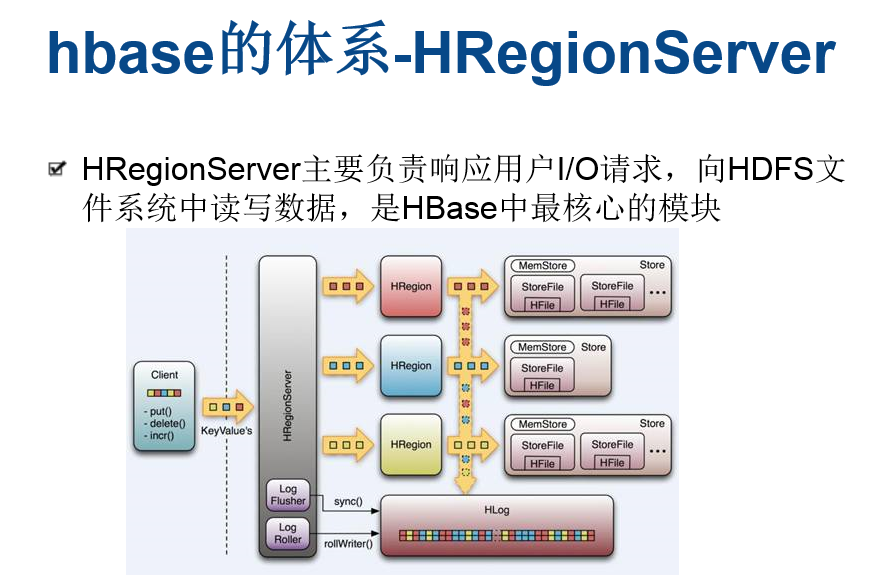
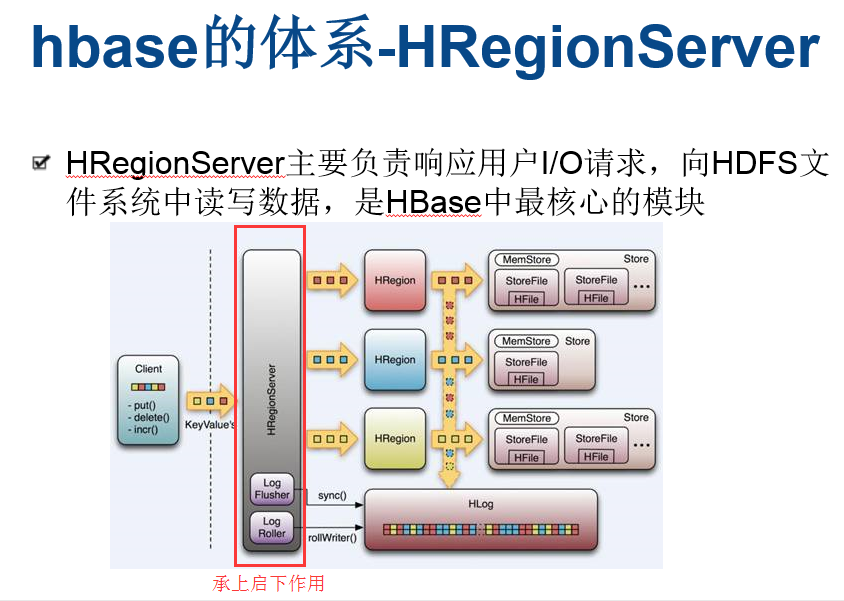
所有的数据库数据一般是保存在Hadoop分布式系统上面的,用户通过一系列HRegion服务器获取这些数据。一台机器上一般只运行一个HRegion服务器,而且每一分区段的HRegion也只会被一个HRegion服务器维护。
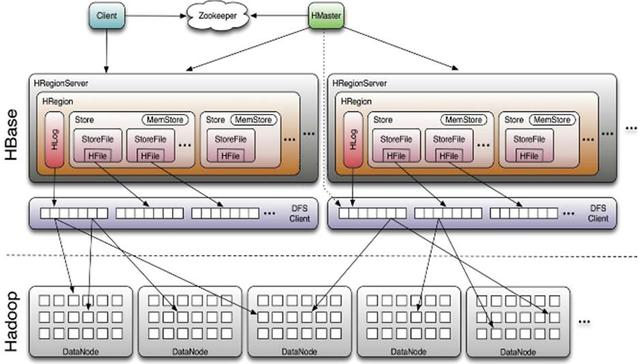
HRegion服务器包含两大部分:HLog部分和HRegion部分。
HRegion服务器在它这里面,又相当于是个小组长。
其中HLog用来存储数据日志,采用的是先写日志的方式。HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。此外,在每一个HStore(又名Store)中有包含一块MemStore。MemStore驻留在内存中,数据到来时首先更新到MemStore中,当到达阔值之后再更新到对应的StoreFile(又名HFile)中。每一个Store包含了多个StoreFile,StoreFile负责的是实际数据存储,为HBase中最小的存储单元。
HBase中不涉及数据的直接删除和更新操作,所有的数据均通过追加的方式进行更新。数据的删除和更新在HBase合并的时候进行。当Store中StoreFile的数量超过设定的阔值时将触发合并操作,该合并操作把多个StoreFile文件合并成一个StoreFile。
当用户需要更新数据的时候,数据会被分配到对应的HRegion服务器上提交修改。数据首先被提交到HLog文件里面,在操作写入HLog之后,commit()调用才会将其返回给客户端。HLog文件用于故障恢复。例如某一台HRegionServer发生故障,那么它所维护的HRegion会被重新分配到新的机器上。这是HLog会按照HRegion进行划分。新的机器在加载HRegion的时候可以通过HLog对数据进行恢复。
当一个HRegion变得太过巨大,超过了设定的阔值时,HRegion服务器会调用HRegion.closeAndSplit(),将此HRegion拆分为两个,并且报告给主服务器让它决定由哪台HRegion服务器来存放新的HRegion。这个拆分过程十分迅速,因为两个新的HRegion最初只是保留原来HRegionFile文件的引用。这时旧的HRegion会处于停止服务的状态,当新的HRegion拆分完成并且把引用删除了以后,旧的HRegion才会删除。另外,HRegion可以通过调用HRegion.clodeAndMerge()合并成一个新的HRegion,当前版本下进行此操作需要两台HRegion服务器都停机。